前提:
代码结构
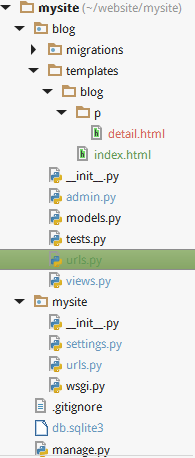
步骤一:
下面为某个网页的链接地址
{% if latest_article_list %} - {% for article in latest_article_list %}
- { { article.title }} {% endfor %}
No articles are available.
{% endif %}其中的链接地址为:
步骤二: 点击链接后,进行URL匹配。 第一层 mysite中的url.py
urlpatterns = [ url(r'^admin/', include(admin.site.urls)), url(r'^blog/',include('blog.urls'))] 第二层 blog中的url.py
urlpatterns = [ url(r'^$', views.index, name='index'), url(r'^p/(?P[0-9]+)/$', views.detail,name='detail')]
步骤三:
然后调用view.detail (在view.py中)
def detail(request, article_id): article = get_object_or_404(Article, pk=article_id) return render(request, 'blog/p/detail.html', { 'article': article})
步骤四:
然后返回 目录 blog/p/detail.html
ARTICLE { { article.title }}
{
{ article.content }}
根据article.id值在数据库中查找相应字段,填充article.title和article.content的具体值。
效果:

需要注意的是地址栏为:

而不是detail.html的目录
移除硬编码
html文件中的链接 { { article.title }} blog中的url.py文件有name参数
urlpatterns = [ url(r'^$', views.index, name='index'), url(r'^p/(?P[0-9]+)/$', views.detail,name='detail')]
所以使用{% url %}标签,链接改为 { { article.title }} 处理多个项目出现相同的detail,使用命名空间
在mysite的url中设置
urlpatterns = [ url(r'^admin/', include(admin.site.urls)), url(r'^blog/',include('blog.urls', namespace='blog')) ] 链接改为
{ { article.title }}